Projects
Neighborhood Comparison in R shiny
- ADS thesis project by Imke Dekkers, Pascalle Wooning & Sara Kellij
- Supervisors: Erik-Jan van Kesteren and Laura Boeschoten
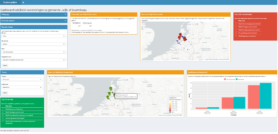
- Abstract: Active participation of citizens is more and more stimulated by governmental institutions. For example, citizens are allowed to contribute to the decision-making process by submitting ideas on how to improve the livability of the neighborhood. Most of the community initiatives are experience-based and not evidence-based or data driven. However, it is not easy for citizens to obtain objective data about different topics of interest. Multiple online dashboards fail to capture and visualize data of boroughs and comparisons between different geographical areas are not possible. Therefore, the current study tries to bridge this gap by developing a dashboard with visualizations of open data and comparisons between geographical areas about topics of interest for citizens.
Read more…
The data that are used are about amenities, health, traffic accidents, and crime as was suggested by citizens of Utrecht Overvecht and consists of three levels: the municipal, neighborhood, and borough level. Direct feedback from citizens of Utrecht Overvecht and scientific researchers contributed to the development process of the dashboard. The feedback resulted in improved understandability and usability of the dashboard designed with R Shiny for citizens of the Netherlands. However, there are indications that the use of this dashboard might still be hard for citizens with poor data skills or low digital literacy. While these challenges still exist, this research can be seen as a first step in making open data more accessible and understandable. The written code to develop the dashboard is published on GitHub to contribute to open science.
- ADS thesis project by Dimitri de Boer, Nina ten Pas, and Bruno Laiber de Pinho
- Supervisor: Anastasia Giachanou
- Abstract: Biases and stereotypes in society can be reflected in different sectors of our everyday life including work environment, education and politics. News and political speeches are only two examples of textual content in which stereotypes are present. In this project, we focus on both gender and racial bias. Using approaches from NLP, first we explore how adjectives are used by female and male politicians (and particular when they refer to male and female gender) . Next, we model the evolution of biased language over the decades using a collection of debates from the UK House of Commons. Finally, we use sentiment analysis to analyze how different races are described in news. Our results indicate that adjectives are used in a different way from male and female politicians and that bias exists across several decades. Finally, we found that articles that discuss ethnic outgroups have a negative tone and emotion.
- ADS thesis project by Joep Franssen, Arleen Lindenmeyer, and Eveline Schmidt
- Supervisors: Ayoub Bagheri and Javier Garcia Bernardo
- Abstract: Scientific misconduct is often a result of the pressure researchers feel to frequently publish papers, which negatively affects the research quality and results in more erroneous studies. Taking a technical approach, we attempted to address this critical issue by building models with the ability to classify retracted and non-retracted published scientific articles. We build several shallow and deep-
learning models to detect erroneous research. We compared the performance of those classifiers for a train/test and external dataset.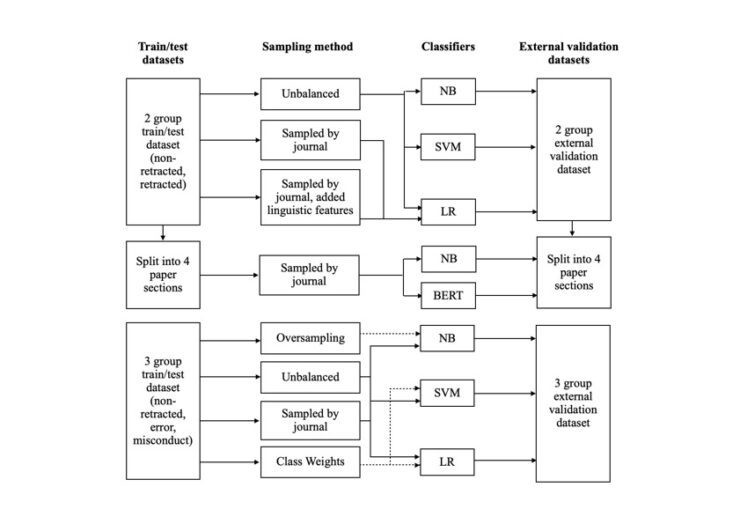 Results show that classifiers can distinguish retracted papers from non-retracted based on texts. The classifiers performed well for papers within the same topic and journal as the classifier was trained on (as in the test set).
Results show that classifiers can distinguish retracted papers from non-retracted based on texts. The classifiers performed well for papers within the same topic and journal as the classifier was trained on (as in the test set).
Read more…
The performance was worse on the external dataset. The linguistic features: quantity of lexicon, complexity and lexical diversity, showed significant differences between retracted and non-retracted papers. Including these five linguistic features did, however, not improve the performance of the classification model based on only texts by Logistic Regression. Further differentiating between non-retracted articles, articles retracted due to error and articles retracted due to misconduct improved the performance of the classifiers in external validation. Class imbalance led to different performances for the classes. When the papers were split into four different sections, the shallow Naive Bayes model performed worse than the deep learning BERT model on the test set. For the external dataset, Naive Bayes performed very similarly and for some sections even better than BERT. All sections turned out to be indicative although the references section turned out to be least predictive for erroneous research detection.
- Although recent works have applied sophisticated NLP methods to quantify social bias in large corpora , there is still limited research regarding the associations between users’ beliefs and social bias expressed in online text.
- In this project, we are interested in filling this gap by exploring whether there are any associations between implicit social bias that different texts express with people’s beliefs on societal topics. In this way we will attempt to understand whether people consume information that confirms their beliefs or not and to which extent.
- Funded by UU Focus Area Applied Data Science (2022) .
Data Donation for the Social & Behavioral Sciences
- Data donation is a method of collecting digital trace data for research purposes. It involves participants requesting and sharing their Data Download Packages (DDPs).
- An overview of the workflow:
- The participant requests their personal DDP from the platform of interest.
- They download the DDP onto their personal device.
- Using local processing, only the relevant features needed for the research are extracted from the DDP.
- The participant reviews the extracted features and can choose to consent or decline to donate.
- If consent is given, the donated data is sent to a server accessible to the researcher for further analysis.
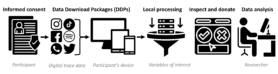
To facilitate the local processing step, the open-source software PORT has been developed. It allows researchers to configure their own data donation study and create a website that guides participants through the process. Researchers can customize the website to suit their specific DDP requirements and desired processing methods.
- For more detailed information about data donation, please visit the data donation website here.
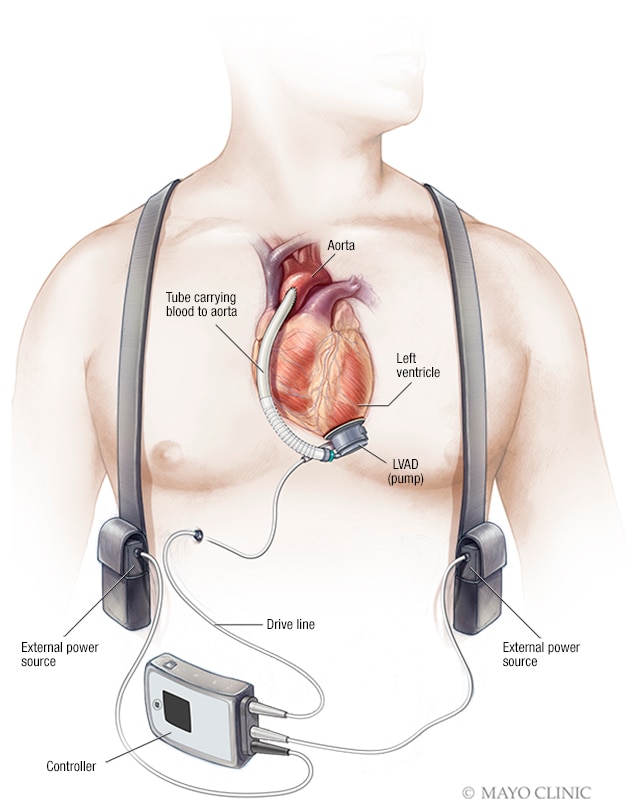
Personalized Remote Patient Monitoring Systems (PRPM)
- EMPOWER: Designing a PRPM system for early-stage heart failure patients by monitoring blood pressure, heart rate, and body weight.
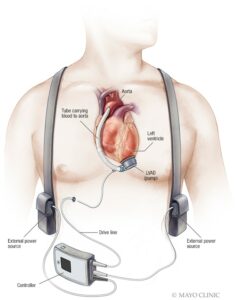
- LVAD: Designing a PRPM system for advanced heart failure patients under the care of a left ventricular assistant device (LVAD).